

A Snowflake data warehouse is a reasonable starting point for healthcare analytics. It scales well and doesn't require you to babysit infrastructure every time data volume spikes.
The problem shows up about six weeks in.
Your data lives across systems that never agreed on a common format. A single patient can exist under four different identifiers across three platforms. Half your feeds claim to follow FHIR, while half don't. And every record you touch carries PHI, which means HIPAA compliance has to be designed in from the start.
The architectural decisions you make before the first row lands in Snowflake determine whether the system holds up. That's what Snowflake services in healthcare focus on.
Why Snowflake Data Warehouse Projects Fail in Healthcare
Healthcare data doesn’t arrive clean
Most of it comes from systems that were never meant to connect, built by different vendors with no shared agreement on what a patient record should look like.
Formats vary. Standards like FHIR (Fast Healthcare Interoperability Resources) exist, but compliance with them is still inconsistent. On any given day, your data pipeline might process structured billing records and raw device streams in the same run, with clinical notes and FHIR responses somewhere in between.
A 2025 study published in the Journal of Medical Internet Research put the cost of that fragmentation at over $30 billion annually for the US health system alone.
Every one of those records potentially contains PHI. That means every step, from ingestion to storage to query, carries HIPAA compliance weight.
Legacy healthcare data warehouses break down
Traditional healthcare data warehouse setups were built for one thing: reporting. They held up fine when the job was generating monthly summaries. They start breaking the moment data volume spikes or security requirements get more specific than a single access role.
A Snowflake data warehouse handles the technical side well. But structuring data before it arrives, and deciding where PHI lives, those are your decisions to make. This realization often arrives at the first compliance review, when the PHI is already in the wrong place
How a Snowflake Data Warehouse Fits Into a Healthcare Architecture
The most common mistake teams make is routing all raw data directly into Snowflake before it's been processed. It works best as a clean analytics layer that receives already-processed data.
A realistic architecture looks like this:
Data Sources → Ingestion → Tokenization → Transformation → Snowflake Data Warehouse → Applications
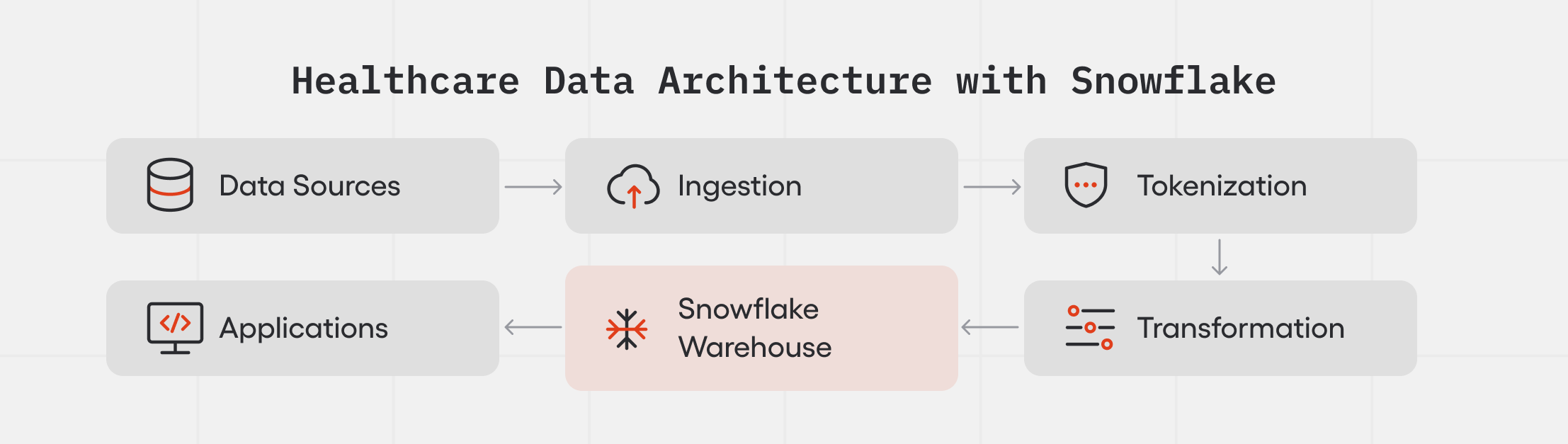
If patient records arrive without a common identifier, every query you run on that warehouse produces the wrong denominator.
What should you prepare before data enters the Snowflake data warehouse?
By the time a record hits your healthcare data platform, it should already be cleaned and standardized, with direct PHI identifiers removed where HIPAA compliance requires it.
Teams that skip this step spend month three rewriting transformations they wrote in week one.
Three Architecture Decisions That Determine How Your Snowflake Data Warehouse Performs
Architecture decision #1: How should healthcare teams handle PHI in a Snowflake data warehouse?
We've seen teams store PHI directly in Snowflake and plan to sort out access controls later. That's where the compliance problems start, and by the first audit they're expensive to unwind.
According to IBM's 2025 Cost of a Data Breach Report, healthcare breaches average $7.42 million per incident, the highest of any industry for 14 consecutive years.
It’s a common mistake to store PHI directly in Snowflake and treat access controls as something to sort out later. That's where the HIPAA compliance problems start. Storing PHI directly in your warehouse expands your HIPAA compliance scope and adds governance overhead that slows the team touching the data.
How to choose between tokenization, encryption, and anonymization
These three concepts get mixed up often, and the difference matters.
Encryption keeps PHI protected but doesn't remove it from your system.
Anonymization removes it for good, which creates its own problem: you can't re-identify a patient even when there's a legitimate clinical reason to.
Tokenization handles both concerns. Sensitive fields get replaced with tokens before data enters your Snowflake data warehouse. The original values live in a separate PHI vault, accessible only through a controlled process. Your analytics layer stays clean. Re-identification stays possible, just not open.
For most healthcare data warehouse architectures, tokenization is the right call.
How tokenization works in a healthcare data pipeline
Raw data enters the system. PHI fields get extracted and replaced with tokens before anything reaches Snowflake. The token-to-identity mapping lives in a separate, secured PHI vault. Your analytics layer never sees raw patient identifiers. This is the architecture that holds up under audit.
MEV success story: how we built a tokenized pharmacy claims platform on Snowflake
Imagine: a patient walks up to the pharmacy counter without knowing their drug plan. Or hands over the wrong insurance card. The pharmacist needs an answer in seconds.
We built the data infrastructure that provides it.
The result: the platform processes over 5 billion rows of US pharmacy claims data at terabyte scale and returns real-time coverage results via API, fast enough for live pharmacy-counter use.
Reload time dropped from 10-12 hours to 2-3 hours. Cost per reload went from over $1,000 to around $50.

How tokenization makes it work
Claims data arrives de-identified through Snowflake Shares. It lands in vendor-native schemas, gets cleaned, standardized, and enriched through ordered SQL transformations, then exports to AWS for serving.
The lookup works like this. When a request comes in, the API accepts the minimum patient details needed for matching: name, date of birth, ZIP code, and gender. That data runs through Datavant tokenization to generate matching tokens. Those tokens are compared against tokenized claims history to identify the most likely PBM (Pharmacy Benefit Manager) and drug plan. The raw input is discarded immediately. It is never written to disk.
The system identifies likely drug coverage in real time without retaining the patient data it used to find the answer.
What the architecture had to solve
Snowflake handled ingestion, transformation, and warehousing well. For serving live API lookups, it was too slow. We designed the pipeline so Snowflake prepares and curates the data, then exports it to a dedicated serving layer built for fast reads. The platform started on Postgres. As data volume grew, the serving layer migrated to SingleStore.
That migration is where the cost and time improvements came from. Same data, better-suited infrastructure for each job.
Snowflake is the right tool for preparing and curating data. It's not built for low-latency API serving. That's why the architecture needs a separate serving layer, and why the migration to SingleStore is where the real performance gains came from.
Architecture decision #2: how should you design your healthcare data warehouse schema?
Schema design looks like a later problem until the platform is live and changing it means rewriting queries against data already in production. By then it's expensive to fix.
Lakehouse vs data warehouse: what works for healthcare?
Data lakes give you flexibility but make governance harder. Traditional warehouses give you structure but struggle when data formats change, which in healthcare they do constantly. Snowflake's hybrid approach lets you store semi-structured data while keeping governance and access control intact.
Flexibility without a clear data model means aggregates that don't match across reports and counts that shift depending on which table you join from.
Master data management in healthcare
In healthcare, that model breaks down before you've finished building it. The same patient arrives from three source systems under three different identifiers, and without a resolved identity layer, your data model has no stable entity to organize around.
Record matching and deduplication are what make your healthcare data warehouse usable at scale.
Skip those steps and the same patient ends up as three different records across your system. Golden record creation gives every downstream query a single authoritative patient record to join against.
How should you structure your healthcare data warehouse schema?
Normalized schemas keep data consistent but slow down queries. Denormalized schemas are faster but introduce duplication risk.
The right choice depends on your query patterns and how closely you need to follow FHIR and HIPAA requirements. Make that call early.
Architecture decision #3: batch vs real-time in healthcare data pipeline design
Pipeline design is where most healthcare data warehouses build up technical debt without anyone noticing until it's too late to fix cheaply. The right choice between batch and real-time depends entirely on what the data is for.
Batch works well for claims processing and historical analysis, workloads where a few hours of latency don't affect outcomes. Real-time matters when the system feeds clinical alerts or patient monitoring, where delays have direct consequences.
Most healthcare data pipelines end up hybrid. Streaming tools capture data changes as they happen. Micro-batching handles efficient loading into the Snowflake data warehouse. The two run in parallel, each handling the workloads it's suited for.
Reliability and observability in a healthcare data pipeline
PHI data quality checks catch missing patient identifiers and malformed records before they reach the analytics layer. Without lineage tracking, you can't answer the regulator's first question: where did this record come from and who touched it.
IBM's 2025 Cost of a Data Breach Report found that healthcare breaches take an average of 279 days to identify and contain, the longest of any industry.
Build observability in before the system goes live. The first incident is a bad time to figure out where your data broke.
How to Build a HIPAA-Ready Security Layer Into Your Snowflake Data Warehouse
Every layer, from data ingestion to storage to serving, needs security decisions made before the build starts.
How does access control work in a snowflake data warehouse?
Snowflake gives you role-based access controls and dynamic data masking. Together they let you enforce strict HIPAA policies without locking out the teams that need to work with the healthcare data warehouse.
Those controls only hold up if the underlying data is structured correctly. A poorly designed schema makes even well-configured security hard to enforce consistently.
What does HIPAA auditability require?
Healthcare systems need a full log of who accessed data, when, and what they did with it. That's a HIPAA requirement, and it's also what makes incidents manageable when they happen. Without it, an incident becomes a regulatory problem.
How does Snowflake support secure data sharing in healthcare?
Healthcare data regularly crosses organizational boundaries, between providers and payers, between platforms, between partners. Snowflake's secure data sharing, combined with tokenization, lets you move data between parties without duplicating datasets. That keeps PHI exposure contained and audit trails clean.
When Does a Healthcare Data Warehouse Project Need an External Team?
In-house builds work until the architecture decisions outpace the team's experience with them. We've seen it happen at both ends: a pipeline under-scaled for the data volume, and a team spending most of its time patching things that should have been built right once.
The decisions that hurt most at month six are usually the ones nobody flagged at kickoff. If the build is already in progress and something isn't adding up, that's exactly when to bring in a second set of eyes. Same if you'd rather get the architecture right from the start.
How to Get a Snowflake Data Warehouse Right in Healthcare
Healthcare data warehouse projects have predictable failure points. PHI handling and schema design are where most early mistakes happen. By the time the pipeline breaks, they're expensive to fix.
We've built healthcare data management platforms processing claims from PBM networks across tens of thousands of pharmacy locations. If you're scoping a build or already mid-way through one that isn't holding up, we're glad to take a look.


.png)


