
Most AI projects fail because the data isn’t ready.
Modern healthcare platforms rely on four layers: FHIR, Warehouse, MDM, API/Access Control.
Steps to build an AI-ready healthcare data architecture:
- Use FHIR-first persistence to standardize clinical data.
- Add fine-grained authorization so AI only accesses permitted data.
- Build a function-calling layer so LLMs retrieve data safely.
- Use RAG to ground AI outputs in real patient data.
- Add a warehouse/ETL pipeline for analytics and ML.
- Enforce privacy and compliance (tokenization, consent, auditing)
Healthcare data is notoriously messy. It’s scattered across EHRs, pharmacies, labs, and insurers, and packed with duplicates, missing fields, and business rules no one has fully written down. With data like that, even the smartest model can’t deliver reliable results.
So before worrying about which model to use, healthcare companies need to build a strong data foundation. Well-governed, well-structured data is what makes AI safe, accurate, and usable in day-to-day workflows. In short, without data readiness, you won’t be able to launch AI.
But how to prepare the healthcare data so AI models can correctly analyze and use it?
At MEV, we’ve had to solve this problem on every AI-related project we delivered. In this article, we put our experience and share a technical how-to guide on building the right healthcare data management architectures, so you can get your data into shape before implementing AI.
Why AI fails so often in healthcare
Too many AI initiatives never reach production (around 80%, to be specific), and the ones that do often deliver inconsistent or low-value results.
After almost 20 years of building software for regulated industries, we’ve seen the same pattern repeat: teams start with the model, not the data, and pay for it later.
AI is blocked not by algorithms but by architecture. More specifically, by the data layer.
Today, it’s faster to spin up a GPT integration than it is to prepare the systems, pipelines, permissions, and governance. But a model is only as good as the data feeding it, and healthcare data rarely comes in clean.
Healthcare data is a patchwork:
- EHRs in one format
- Pharmacies in another
- Payers in proprietary schemas
- Labs in HL7
- Third-party vendors delivering CSVs, PDFs, XML, or Snowflake Shares
- Legacy systems are still running on decades-old standards
And each one has its own undocumented logic and exceptions.
AI is not magic. And healthcare absolutely refuses to be fooled.
That’s why you need to start with a data foundation first.
4 main layers for AI in healthcare data management
Here’s the comparative overview of the 4 main architecture layers healthcare platforms now follow.
1. FHIR-first operational data layer
This is the system’s real-time brain. FHIR is a general-purpose, HL7-based standard that evolved from HL7 v2 and HL7 v3/CDA to support modern, web-friendly clinical interoperability. It makes clinical data understandable: with shared semantics across resources like Patient, Observation, MedicationRequest, Encounter, and Condition, different apps and systems can speak the same language without endless mapping.
It lets hospitals, labs, payers, pharmacies, and EMRs exchange data without chaos, while other standards focus on more specific needs like long-term data storage, research analytics, or regulatory submissions.
FHIR covers broad, real-time clinical interoperability, and it’s typically used together with more purpose-specific standards rather than instead of them. The main ones include:
2. Warehouse / Lakehouse analytics layer
If the FHIR store is the brain, this layer is the memory palace.
Snowflake, BigQuery, and Databricks collect cleaned and standardized data through ETL pipelines. Here’s what it supports:
- Population health dashboards
- Longitudinal patient journeys
- Predictive modeling on de-identified datasets
- Quality metrics
- Cost and risk analytics
This layer makes cross-patient analysis possible.
3. MDM / hMDM (Master Data Management) layer
Healthcare data often looks structured but is full of duplicates and mismatched identities.
MDM reconciles patient, payer, provider, and plan records into consistent, trustworthy golden records.
Without this layer, everything above it is built on sand.
4. API & access control layer
REST, GraphQL, and FHIR APIs expose data in predictable, secure, versioned interfaces. This is where permission logic, auditing, masking, purpose-of-use checks, and field-level controls live.
It’s also the layer AI systems interact with, making it the gatekeeper for safe automation.
Let’s sum up:
Now, let’s break down exactly how to build this architecture step by step.
How to build an AI-ready healthcare data architecture in 6 steps
Below, we gathered our experience working on AI healthcare projects, so you can follow the guide and prepare the data for AI implementation.
Step 1: Start with FHIR-first persistence
The foundation of an AI-enabled healthcare system is structured, standardized clinical data. FHIR is the modern standard for this, and using it as your canonical model simplifies almost everything that follows.
Here’s what a FHIR-first model does:
- Eliminates schema chaos. Every patient, encounter, observation, medication, and condition follows a well-defined contract.
- Removes 70–80% of one-off mapping work. Third-party systems already speak in FHIR or can be transformed into it with predictable pipelines.
- Makes interoperability the default. Hospitals, labs, pharmacies, and payers plug into the same structure instead of bespoke integrations that break on every release.
- Gives AI assistants a shared language. When LLMs call functions like get_patient_observations(), they always receive consistent FHIR resources.
- Future-proofs the system. New modules, apps, or AI tools can plug in without restructuring the data model each time.
Here’s what this looks like in practice.
Case in point: How MEV built a FHIR-first patient engagement & compliance platform
Our client needed a scalable ecosystem to manage complex treatment programs across patients, providers, pharmacies, and administrators. Instead of stitching together ad-hoc schemas, we designed the platform from the ground up on FHIR v4.
The system synchronized with external EHR and pharmacy systems using native FHIR APIs, ensuring automatic interoperability. A HAPI FHIR server handled real-time read/write, while strict resource-level permissions (RBAC + ReBAC + FHIR Security Mechanisms) enforced who could see which parts of a record.
Here’s what we achieved thanks to the FHIR-first approach:
- Zero custom schemas → dramatically reduced mapping overhead
- Easy multi-application integration (patient app, provider app, admin app)
- Built-in compliance through resource-level access controls
- The platform became AI-ready by design, without refactoring
A FHIR-native foundation eliminates the most common barriers to AI adoption later.
Step 2: Add an authorization & permission layer
Before AI interacts with any clinical data, you need fine-grained permission control, far stricter than standard application RBAC.
This layer decides what data the AI is allowed to access on behalf of the user.
Here are the required capabilities:
- User-specific access (patients see their own records; doctors see their patients)
- Purpose-of-use checks (research access vs. treatment access)
- Contextual restrictions (time-of-day, role, break-the-glass events)
- Full audit logging (every retrieval must be traceable)
For example, when a user asks an AI assistant, “What were my last blood test results?”, here’s what happens behind the scenes:
- The AI authenticates the user
- The authorization layer checks:
- Is this the patient?
- Are they allowed to see Observations?
- Only authorized FHIR resources are retrieved
- AI summarizes them in natural language
This prevents accidental overexposure of PHI, one of the biggest risks with AI in healthcare.
Here are the tools that can help:
- Permit.io (fine-grained AI access control)
- Permify
- OPA/ABAC-based custom solutions
Step 3: Build a tools/function calling layer
This is the layer that allows AI to act like a smart agent instead of a chatbot guessing answers.
On the platform side, you already have your four main layers:
- FHIR as the operational backbone
- Warehouse/lakehouse for analytics
- MDM for identity consistency
- APIs for controlled access
On top of that, you add one more piece specifically for AI: a small, well-defined set of tools (functions) that an LLM can call instead of communicating with APIs directly.
LLMs like OpenAI and Claude support function calling, which means the model doesn’t invent SQL or URLs; it chooses from a toolbox you’ve given it. Each tool is a narrow, controlled operation against your data.
For example:
- get_patient_observations(patient_id, category)
- get_patient_conditions(patient_id)
- get_patient_medications(patient_id)
- search_encounters(patient_id, date_range)
From the AI’s point of view, the flow looks like this:
user asks a question → AI picks a tool → the tool checks permissions → queries FHIR or other sources → returns structured data → AI explains the result in natural language.
This way, the model never has raw, free-form access to your FHIR store or warehouse. It only operates through a thin layer you control.
Step 4: Add RAG to reduce hallucinations
Even the best LLMs hallucinate if they don’t have real data. RAG solves this by injecting verified FHIR data into the prompt.
In practice, RAG (Retrieval-Augmented Generation) is an AI framework that acts as the “source of truth” mechanism for AI assistants. Instead of letting the model guess, you retrieve the exact FHIR resources needed for a question, like the patient’s MedicationRequest, related Condition, and recent Observations, and pass only those into the model as context. This keeps the AI grounded in structured, real clinical data, dramatically reducing hallucinations and ensuring every answer is traceable back to a specific FHIR record.
Here’s how it works when the user asks, for example, “Why was I prescribed this medication?”:
- Tool retrieves:
- MedicationRequest
- Related Condition
- Relevant Observations
- RAG injects these into the model as context
- AI generates an answer grounded in real patient data
The main consideration is that privacy must be handled carefully. For this:
- Only inject the minimum necessary fields
- Mask identifiers (e.g., SSN, address)
- Keep audit logs of every injection
- Use zero-retention LLM modes so no patient data trains the model
This approach produces precise, safe patient explanations and avoids liability from hallucinated medical guidance.
Step 5: Add a warehouse / ETL path for cross-patient analytics
AI assistants usually operate at the single-patient level. But population-level insights still matter, like quality metrics, reporting, or dashboards.
For that, FHIR data is ETL’d into a warehouse (Snowflake, BigQuery).
What this enables:
- Population health dashboards
- Provider quality metrics
- Cohort discovery
- Predictive modeling on de-identified data
- Benchmarking and operational analytics
Here, permissions are critical. Only a very small group (analysts, admins) should access cross-patient analytics. AI assistants working at the patient level should not see aggregated patient data unless explicitly permitted.
Case in point: How we delivered a Snowflake-first claims intelligence platform
Our client needed to infer a patient’s drug insurer at the pharmacy counter, even when patients presented the wrong card. The raw inputs were massive, vendor-supplied pharmacy claims, each in different schemas, with frequent format changes and limited documentation.
We built a Snowflake-first architecture that ingested claims via Snowflake Shares, normalized schemas, validated formats, standardized codes, filled missing fields through enrichment, and applied tokenization for safe identity matching.
Then, we added a multi-layer MDM approach (deterministic → probabilistic → ML-assisted) to reconcile payer, PBM, and plan into a golden record.
The key results it gave:
- A unified, validated claims repository
- Real-time coverage inference via a low-latency API
- Strong privacy posture (tokenization, no raw PII stored)
- Future-proof foundation for ML-driven payer/plan prediction
- Resilient data pipeline with schema drift protection and quality gates
The warehouse makes population-scale claims data usable.
Step 6: Add privacy-preserving & compliance controls
This is the layer that turns your architecture from functional to regulatory-safe.
Here are the core safeguards required:
- Data minimization: AI only sees what’s needed
- De-identification for ML training: using Expert Determination or Safe Harbor
- Tokenization/encryption: especially for identities, genetics, or sensitive observations
- Consent enforcement: AI must respect patient opt-outs
- Comprehensive audit logging: every field accessed, by whom, for what reason
- Zero-retention LLM operation: ensuring AI providers don’t train on PHI
Compliance must be woven into the architecture; otherwise, the product won’t be safe.
Here’s what the final architecture looks like:
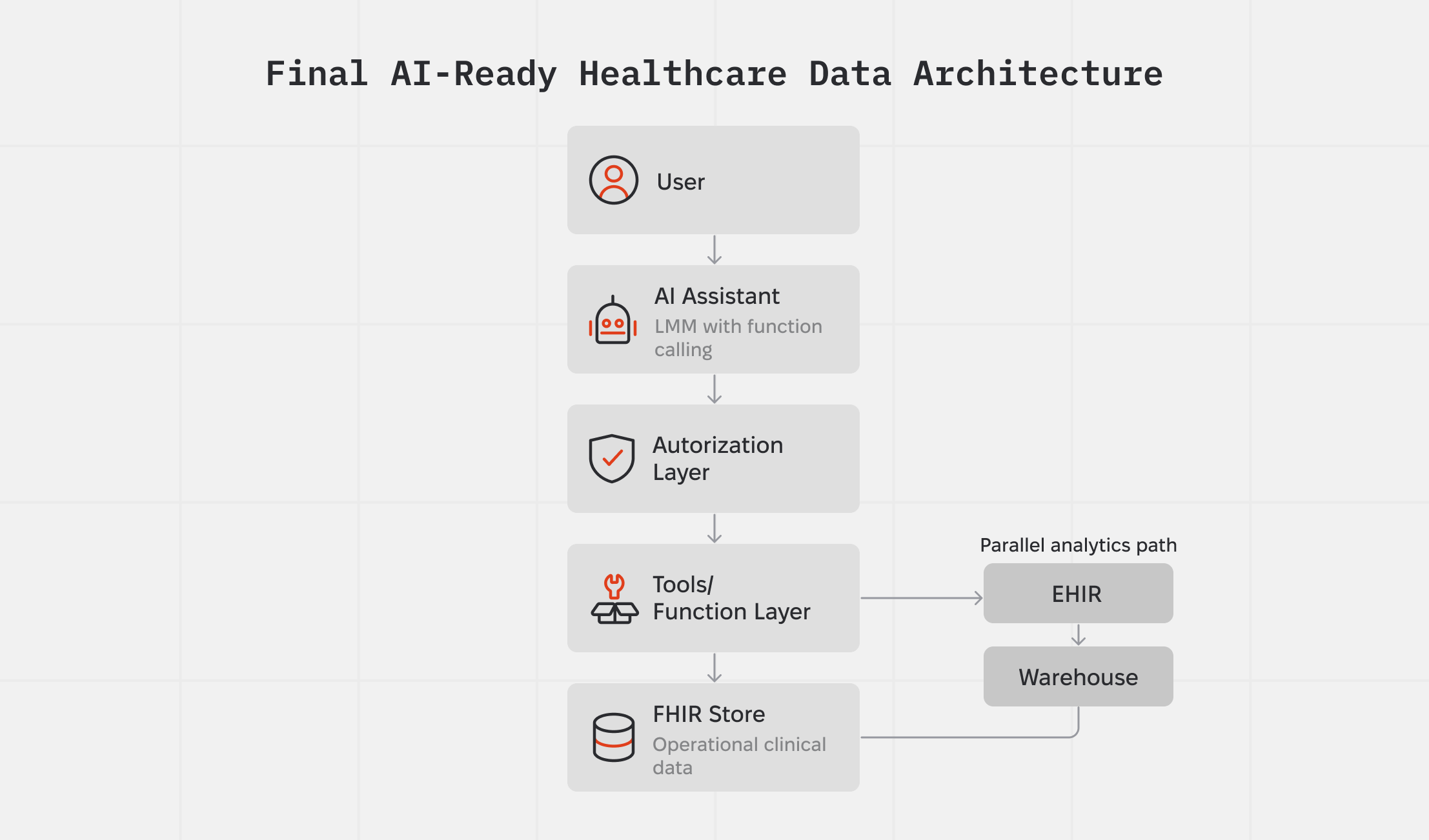
What this architecture enables:
✔ AI assistants that can act on behalf of users, with their exact permissions
✔ Strict HIPAA/GDPR compliance driven by technical enforcement
✔ Safe, contextual retrieval of clinical data
✔ Explainable, traceable AI behavior
✔ Ability to scale by simply adding new functions without redesigning the system
✔ No need for custom models, only LLMs + structure
Bottom line: AI success starts with data
AI readiness in healthcare has far less to do with picking the “right” model and almost everything to do with the shape of your data and systems.
If your architecture is built on structure, permissions, auditability, and controlled data access, then you can confidently plug LLMs into clinical workflows. If it’s not, no model will be safe or trustworthy enough.
At MEV, we’ve spent almost 20 years shipping software in regulated environments, including healthcare. We’ve lived through HIPAA, GDPR, SOC 2, ISO 27001, shifting AI guidance, and our take is simple: regulation isn’t the bottleneck, sloppy architecture is.
If you’re planning an AI initiative in healthcare, we can help with the part most vendors gloss over: getting your data and architecture AI-ready. Tell us what you want to build, and we’ll give you a straight answer on what it will take in time, scope, and budget.





