

When your software is stable, secure, and easy to maintain, it’s more than “IT running smoothly” — it’s a competitive advantage. Healthy applications keep teams productive, customers happy, and growth plans on track.
Poor maintainability has a price: downtime, emergency fixes, rushed deployments, and missed deadlines. Every hour lost chips away at revenue and client trust.
Running seven targeted maintainability checks has delivered results like:
- 92% lower infrastructure costs by removing unused resources and optimizing hosting.
- 3× faster system performance
- Zero outdated dependencies that could trigger security or compliance risks.

These aren’t abstract “best practices.” They’re measurable outcomes from reviewing how your software is built, deployed, and maintained.
Check #1 – Documentation & Workflow Clarity
We often see the same gaps: no infrastructure diagram and a README missing core details.
The cost: every incident drags on because developers must reverse-engineer the system before fixing it. Missing infra diagrams make it worse — no one knows how servers, services, and databases connect, so outages take longer to diagnose and costs stay hidden.
Branching chaos adds another layer: without a clear workflow, code merges cause conflicts that ripple into infra misconfigurations across staging and production.
What works in practice:
- Keep a one-page infra diagram in the repo showing servers, services, and data flows.
- Add a README with setup steps, environment variables, and deployment notes.
- Document a branching workflow (e.g., Git Flow).
With these basics, onboarding takes hours instead of weeks, incidents are resolved in minutes, and costly infra blind spots are easier to catch.
Check #2 – Dependencies
Every app depends on third-party libraries and frameworks. Left outdated, they create security gaps, compliance risks, higher upgrade costs, and integration delays.
They also tie directly to infrastructure. Old frameworks often only run on outdated OS or database versions. In one audit, legacy .NET dependencies kept a client stuck on Windows Server already past end-of-life — no security patches, higher infra bills, and a rushed migration when their cloud provider dropped support.
What a healthy dependency profile looks like:
- All libraries on current or supported versions.
- No deprecated or unmaintained packages.
- End-of-life platforms flagged and scheduled for upgrade.
- Updates baked into regular release cycles.
Practical actions to keep costs down and risks low:
- Maintain a live inventory of dependencies.
- Flag outdated or unmaintained ones.
- Prioritize upgrades: security → compliance → performance.
- Automate scans to catch drift before it locks you to obsolete infra.
Check #3 – Build Stability & Cleanliness
In some of our audits, the builds ran without errors — but they still failed key maintainability checks. In one case, 12 deprecated dependencies were still in use. In both, dozens of libraries were behind their latest stable versions (84 in one case, 17 in another).
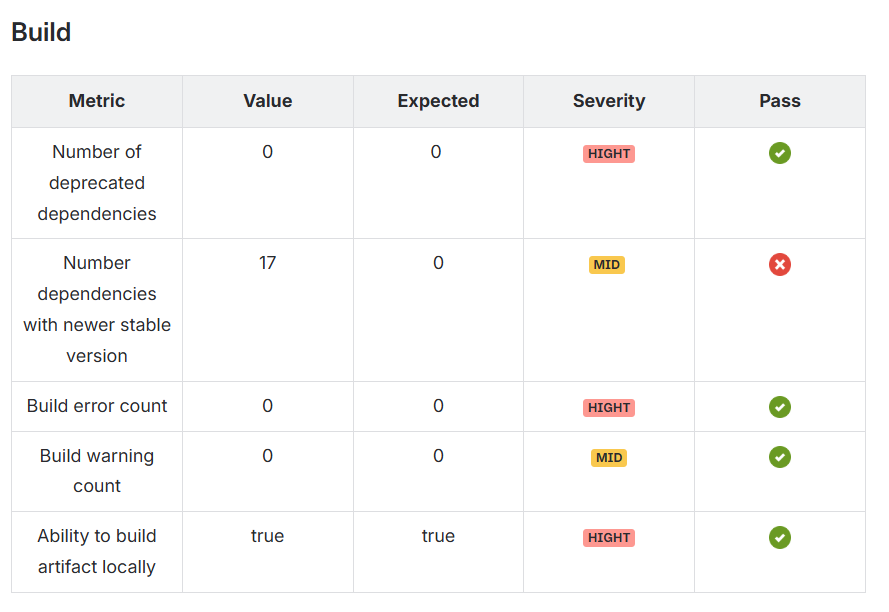

The hidden trap: a technically working build that silently drifts below the hygiene baseline.
The practical fix:
- Remove deprecated dependencies.
- Upgrade in small batches.
- Automate checks so drift is flagged early.
This turns “it builds” into predictable, compliant delivery.
Check #4 – Runtime Readiness Across Environments
The app should run the same way locally, in Docker, and in CI. In one audit, Docker startup failed even though local runs worked fine.
That gap is infra drift: different configs or dependencies across environments. It blocks automated testing, slows deployments, and makes disaster recovery unreliable because the containerized version doesn’t behave like production.

Close that gap by:
- Version-controlling environment definitions (Dockerfiles, configs, env vars).
- Running container builds as part of CI, not just before releases.
- Standardizing dependency versions across local, staging, and production.
Check #5 – Test Coverage & Quality Gates
Picture this: a release goes live with almost no testing. The build passed, but a change broke a high-revenue workflow. Refunds followed, and a week of planned work was lost.
The alternative: unit tests validate business logic, integration tests verify end-to-end flows, and gates block the release if they fail.
What works in practice:
- Design unit tests around core business logic where silent errors would be most costly.
- Build integration tests for the workflows tied to revenue and compliance.
- Set measurable coverage thresholds (e.g., no drop below agreed baseline) and enforce them in every build.
- Review coverage quarterly to ensure new features are included.
- Block deployments if either unit or integration tests fail — even if it delays the release.
The result: fewer failures in production and steady delivery schedules.
Check #6 – Deployment & Release Reliability
Releases that require manual steps are brittle. A missed database migration or wrong artifact version can stop orders from processing and trigger payment failures.
In one audit, CI handled builds and deployments automatically with no manual DB steps — a strong baseline.

The risky opposite: code pushed from laptops, migrations run by hand, configs managed outside version control. In that setup, infra is inconsistent, and every release risks breaking production.
If your process matches the risky scenario above:
- Automate what can be automated — Start with build, deploy, and database migration scripts. Even partial automation reduces the risk of skipped steps.
- Add environment checks — Scripts should verify they’re running in the right environment before making changes.
- Version control deployment configs — Keep Dockerfiles, manifests, and migration scripts in the repo so they’re reviewed alongside code.
- Run pre-deploy validations — Check dependencies, schema changes, and integration endpoints before deployment starts.
- Implement a rollback path — Always have a tested, fast way to return to the last stable version.
Check #7 – Long-Term Maintainability & Lifecycle Planning
Every OS, framework, and database has a support clock. Ignore it, and you’ll face an urgent, unbudgeted upgrade.
Examples from audits:
- Safe: Windows Server 2022 — supported to 2026 (extended 2031).
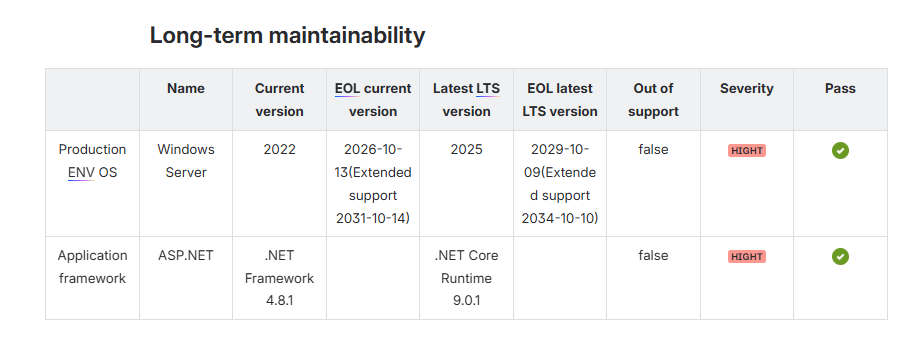
At risk: CentOS 7 (EOL since 2020), MySQL 5.7 (EOL 2023) — both now compliance liabilities.
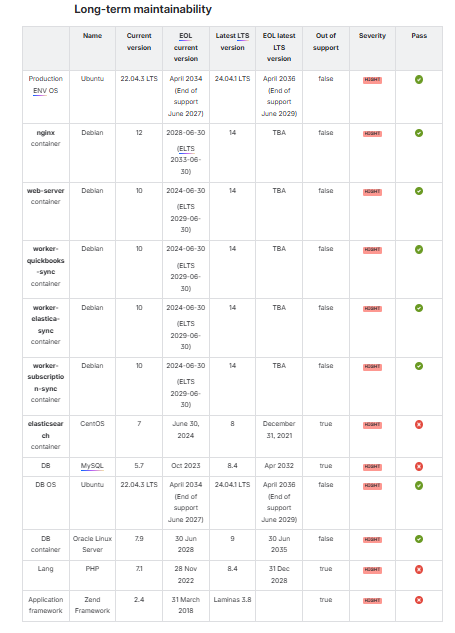
Practical next steps if you find at-risk components:
- Inventory & calendarize: Maintain a live inventory of all OS, frameworks, and DBs with their EOL dates. Treat it like a renewal calendar.
- Align with business cycles: Schedule major upgrades during low-traffic periods to minimize impact.
- Bundle upgrades: Combine component updates to reduce repeated regression testing and release overhead.
Have a “last resort” plan: For any component past EOL, decide if you’ll use paid extended support, container isolation, or an immediate migration.
Final Words
Software doesn’t stay healthy on its own.
These seven checks surface issues before they disrupt operations or budgets. Run them regularly, track results, and fold fixes into normal release work. That’s how you keep systems predictable, teams focused, and business plans on schedule.

.gif)



