

An audit is the moment you decide what your next quarter, and sometimes your next year, will look like.
The findings are only useful if they trigger action. If a payment system’s encryption is out of date, the question isn’t “Is this a problem?” — it’s “What’s the fastest, least disruptive way to modernize it before it costs us money or trust?”
In practice, the post-audit phase is where the business impact happens. This is when you:
- Rank issues not by technical neatness, but by their effect on revenue, risk exposure, and delivery speed.
- Decide which risks you can carry for now, and which ones you need off the table before they disrupt operations.
- Sequence improvements so you see meaningful gains early, even while tackling long-term fixes.
Handled well, the period right after an audit is not about patching holes — it’s about turning identified weaknesses into a roadmap for stronger, more adaptable systems.
In the next section, we’ll break down exactly what a software and applications audit uncovers, using real examples from our maintainability review, cryptography modernization assessment, and full technical audit — and show how those findings translate into clear business priorities.
What an Audit Reveals
A good software and applications audit is a deep look at how well your systems can support the business today and adapt tomorrow. While every audit is unique, the findings usually fall into three focus areas: maintainability, security, and operations.

Maintainability — How Easy (or Painful) It Is to Evolve Your System
When technology stacks are outdated or overly complex, even minor updates demand disproportionate effort. Routine feature releases slow down, testing cycles get longer, and the risk of introducing new issues increases. In some cases, the system becomes so brittle that adding new features isn’t realistically possible without first modernizing the foundation. This drives up delivery costs, reduces development velocity, and can make modernization prohibitively expensive.
That’s not theory — we saw it firsthand in one audit. The foundation was already past its support window (PHP 7.1 and Zend Framework 2), with key components no longer maintained. Several dependencies were deprecated, meaning they could be removed from public repositories without warning. Under these conditions, any attempt to introduce new features or even apply bug fixes risked triggering a cascade of breakages, effectively turning routine maintenance into a potential rebuild scenario.
Security — How Well the System Defends Itself
In an audit, “security” is about whether sensitive data stays protected at every stage — in storage, in transit, and during processing — and whether the system meets the standards required by regulators, payment processors, and partners. Weaknesses in this area don’t just increase the chance of a breach; they can stop the business in its tracks. For example:
- Payment encryption that uses outdated algorithms no longer accepted under PCI DSS, triggering failed compliance audits.
- Authentication processes that lack multi-factor verification, making accounts easier to compromise.
- Encryption keys that are never rotated, increasing the window of opportunity for attackers.
When these weaknesses exist, the impact can be halted payment processing, regulatory fines, mandatory customer notifications, and lost contracts — all while competitors keep running.
One audit uncovered a payment system still relying on deprecated mcrypt encryption in PHP 7.1, a method no longer available in supported PHP versions and already flagged as insecure. This not only created an immediate PCI DSS compliance risk but also posed a hard block to any system upgrades. Compounding the issue, the cryptographic logic was tightly coupled to an obsolete API, making replacement more complex and costly. Without intervention, a routine PHP update could have rendered all historical payment data unreadable — effectively cutting off revenue from existing customers.
Operations — How Reliably the System Runs Day-to-Day
A system’s ability to deliver consistent service isn’t just about preventing failures — it’s about limiting the impact when they occur. The faster an issue is detected, diagnosed, and fixed, the lower the cost to the business. Without robust monitoring, automated alerts, and centralized logging, even minor disruptions can escalate into hours of downtime, multiplying both financial loss and reputational harm.
From an infrastructure standpoint, weak observability and fragile deployment pipelines are often the root cause. When monitoring and automation aren’t built into the stack, teams end up firefighting blind.
In one audit, the risks showed up in several ways:
- No automated monitoring for third-party integrations meant external service outages could go unnoticed for hours.
- Manual deployment processes slowed recovery during urgent fixes, prolonging service interruptions.
- Limited incident traceability in both application and infrastructure logs made it difficult to link production failures back to specific code or environment changes, delaying resolution and driving up operational costs.
- Aging containers and OS versions added further risk, since unsupported infrastructure components lacked patches and forced manual workarounds during incidents.
From Findings to a Business-Focused Plan
An audit produces a list of issues. A good plan turns that list into a sequence of actions that delivers the most value in the shortest time.
We do that by combining formal scoring with client context so that technical priorities and business priorities align.
Scoring the Findings
Each item from the audit is scored on three dimensions:
- Impact — How much it affects revenue, customer experience, or operational performance.
- Urgency — How quickly it must be addressed to prevent escalation or costly downtime.
- Compliance Risk — Whether it exposes the business to regulatory penalties, contractual breaches, or reputational harm.
A finding that rates high on all three is a clear top priority. One that rates high on impact but low on urgency might still be scheduled early if it supports a strategic launch or reduces long-term costs.
Adding Qualitative Input
The numbers alone don’t make the plan. We sit down with both technical leads and business stakeholders to understand:
- Which systems are most critical to ongoing operations?
- What’s on the product or release roadmap?
- How much operational disruption can the business absorb during fixes?
This step often reshuffles the priority list. A “medium urgency” operational issue can jump to the top if it threatens an upcoming seasonal sales peak.
Example from the Case
Once we scored each finding for impact, urgency, and compliance risk, the top priorities almost picked themselves. We then mapped them directly to the four main steps in the modernization plan so that the most critical problems were fixed first.
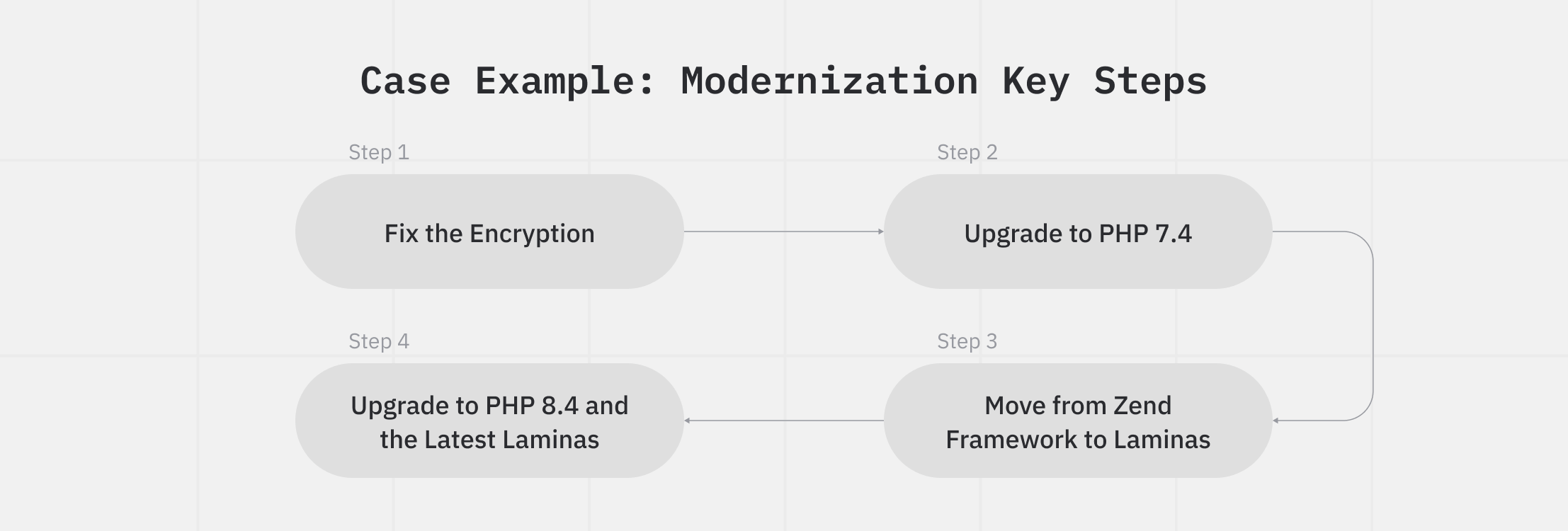
Step 1 — Fix the Encryption
The system was using outdated, insecure technology (mcrypt) to store payment data. It’s no longer supported, fails today’s PCI DSS standards, and could make customer data permanently unreadable during any future upgrade.
Why it came first: Without fixing encryption, the company risked fines, higher payment processing costs, or even losing the ability to take payments. It was also blocking every other upgrade on the list.
Step 2 — Upgrade to PHP 7.4
The application was still running on PHP 7.1, which hasn’t been supported since 2019. That meant no security patches, growing compatibility issues, and higher costs to maintain outdated code.
Why now: Moving to PHP 7.4 created a safe, stable base for future upgrades and made it possible to start replacing outdated components without breaking the system.
Step 3 — Move from Zend Framework to Laminas
The core framework and several key components were abandoned by their maintainers. This made the system harder to update, more expensive to maintain, and at risk of becoming impossible to run if certain libraries disappeared.
Why it mattered: Switching to Laminas put the system back on an actively supported framework, lowered long-term maintenance costs, and removed a big obstacle to staying current.
Step 4 — Upgrade to PHP 8.4 and the Latest Laminas
Once the framework and components were modernized, the final step was moving everything to the latest stable versions.
Why it’s the last step: This positions the system for years of smooth updates, stronger security, and faster delivery of new features — without having to fight against outdated tools at every turn.
By tackling the highest-risk, highest-impact problems first, the plan made sure every upgrade not only improved the technology but also delivered clear business wins — restoring compliance, reducing risk, and setting up the company for faster, safer growth.
Translating Technical Fixes into Business Outcomes
Once priorities are set, the value of each technical fix must be expressed in terms the business measures: cost avoided, revenue protected, and risk reduced. This turns an upgrade plan from a “technical to-do list” into a business case.
Linking Fixes to Measurable Impact
Technical upgrades rarely exist in isolation — each change ripples through compliance status, operational resilience, and delivery speed. For example:
- Compliance: Replacing insecure encryption removes the risk of PCI DSS failure, avoiding fines in the tens or hundreds of thousands and preventing interruptions to payment processing.
- Operational Efficiency: Moving off unsupported PHP versions reduces security incidents and lowers the cost of emergency patching.
- Delivery Velocity: Migrating to a supported framework shortens development cycles and reduces the cost of adding features.
What the Fixes Could Deliver
Afterword — The Real Payoff Happens After the Audit
An audit will reveal where you stand.
Modernization builds momentum:
- Compliance becomes predictable — no scrambling before audits, no surprise outages because a partner cut off access over security concerns.
- Upgrades stop being disruptive projects and become routine, low-cost changes folded into normal delivery.
- Teams spend more time shipping features and less time firefighting, because the foundation supports speed without compromising quality.
- Future opportunities open up faster — from integrating new payment platforms to adopting AI-driven services — without months of rework.
In competitive markets, these aren’t “IT improvements.” They’re the difference between being the company that reacts to change and the one that’s ready before it happens.





